

In today’s information security, the protection of information data is not only a legal obligation, it is critical for the survival and profitability of institutions.
With the reduction of storage costs, organizations began to store their data for longer periods. One day (in time of need) they will start examining all this big data for useful data. But big data can cause serious problems. Most of what is collected may be redundant, old, unimportant (ROT) or unknown (dark) and have been untouched for years.
Storage costs may be low, but they are not free. Storing large amounts of data unnecessarily increases costs and, more importantly, puts your organization at risk.
Sensitive information stored digitally – including intellectual property, that personally identifies information about customers or employees such as social security numbers, protected health information (PHI) and/or financial account information and credit card information – needs to be appropriately secured. If finding important data is like looking for a needle in a haystack, the organization is not safe.
A new cybersecurity report has revealed that 80 percent of companies fail to discover and track sensitive data, not content with identifying where their critical data is replicated and where it moves across their networks.
The Role of Data Classification
- To ensure effective security, you must first identify the exact data(s) you are trying to protect.
Data classification is a critical step. - It enables organizations to identify the business value of unstructured data at the time of creation, separate valuable information that can be targeted from less valuable information, and make informed decisions about resource allocation to ensure data is protected from unauthorized access.
- The information is divided into predefined groups that share a common risk, and the security controls needed to secure each type of group are defined. To improve the processing and handling of sensitive data; classification tools can be used and a culture of security that raises awareness of data sensitivity can be promoted so that it is not inadvertently disclosed and sensitive content is not stored on removable media or third-party web portals.
- Data with attention-grabbing warning labels can change our behavior by making us aware of the dangers that could cause us harm. Visual labels and watermarks such as “Confidential” can remind users to think twice and be more careful with digital and printed data.
- Successful data classification drives the security controls applied to a particular dataset and helps organizations meet legal requirements (such as KVKK/GDPR) to retrieve certain information within a specified period of time.
Keys to success
- While data classification forms the basis of work to ensure that sensitive data is used appropriately, most organizations fail to set the right goals and approach. This causes applications to become overly complex and fail to produce practical results.
- There are 7 steps for effective data classification:
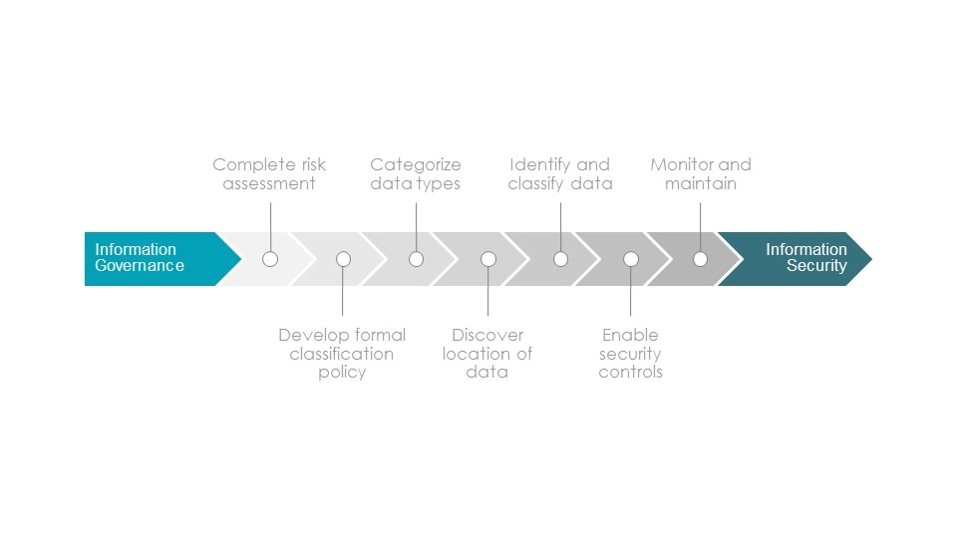
- Complete the risk assessment of sensitive data
- Make sure you clearly understand the organization’s regulatory and contractual confidentiality and confidentiality requirements, and define your data classification goals in an interview-based approach involving key stakeholders, including compliance, legal and business unit leaders.
- Develop a formal classification policy
- Resist the urge to be too granular, as granule classification schemes tend to cause confusion and become unmanageable. Three to four categories of classification are reasonable. Reinforce employee roles and responsibilities. Policies and procedures should be well defined, appropriate to the sensitivity of certain data types, and easily interpreted by employees.
Below is an example data classification scheme: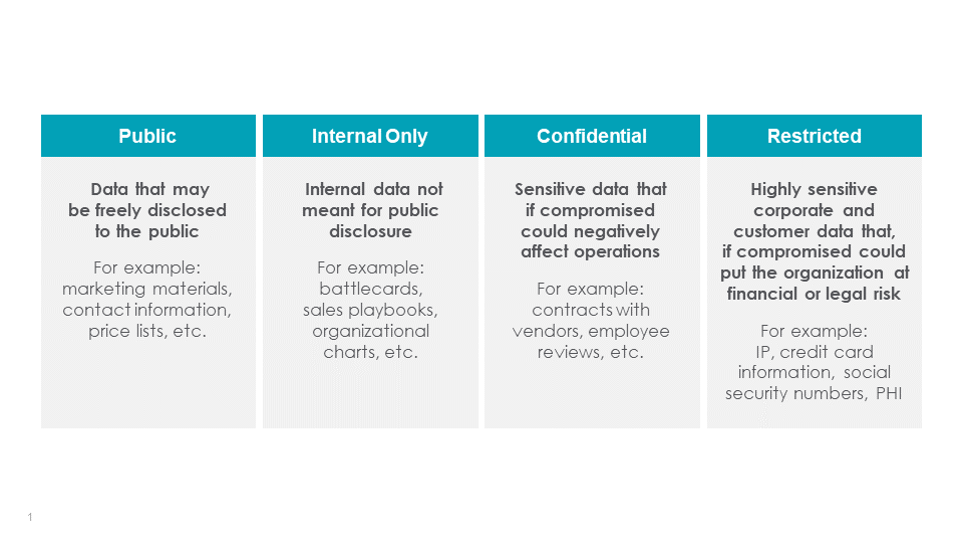
- Each category should detail the types of data it contains, guidelines for handling the data, and the potential risks involved.
- It may be helpful to classify the parent (most sensitive) category with subcategories to indicate regulations or different access control models that may be required. Some of the subcategories that can be added for clarity
- PCI (Cardholder) Data
- Related to HIPAA
- Related to GDP
- Unpublished Financial Data
- Once your policies are completed and communicated, end users should categorize all newly created and recently accessed data from that day forward before turning their attention to old data.
- Categorizes data types
- Some difficulties may arise in the process of determining what kind of sensitive data is available in your organization. It is an effort that needs to be organized around business processes and directed by the process owners. Consider each of your business processes – monitoring the data flow gives you insight into what data should be protected and how. Consider the following questions:
- What customer and partner data does your organization collect?
- What data are you creating about them?
- What proprietary data are you creating?
- What transaction data are you handling?
- Of all the data collected and created, what are the hidden ones?
- Discover where your data is
- Once you have established the data types in your organization, it is important to catalog all the places where data is stored electronically. Data flow into and out of the organization; is a key issue. How does your organization store and share data internally and externally? Dropbox, Box, OneDrive, etc. Do you use cloud-based services? What about mobile devices?
- Data discovery tools can help inventory unstructured data and help you understand exactly where your company’s data is stored, regardless of format or location. These tools also provide information about users who process data, helping to overcome difficulties in identifying data subjects. You can include keywords or certain types or formats of data in your discovery efforts, such as medical record numbers, social security numbers, or credit card numbers.
- Identify and classify data
- Once you know where your data is stored, you can only define and classify it to ensure it is appropriately protected. You can consider penalties for loss or violations.
For example, what penalties per record might be incurred for a HIPAA violation involving protected health information? Learning about the potential costs associated with creating a dataset will allow you to set your expectations for the cost of maintaining it and what level of classification to set. - Commercial classification tools enable data classification processes by facilitating the identification of appropriate classifications and then adding the classification tag to the item’s metadata or applying it as a watermark. Effective classification systems are user-oriented, offering system-recommended and automated features:
- Providing custom data classification options menu. Presenting content within a dataset followed by classification options for user selection.
- Automation where the system selects the appropriate classification based on analysis engines with limited (if any) user input.
- Enable controls
- Enable controls. Take cyber measures for key solutions and define policy-based controls for each data classification tag to ensure that appropriate solutions are implemented. High-risk data requires more protection, while low-risk data requires less protection. By understanding where the data resides and the organizational value of the data, you can apply appropriate security controls based on the associated risks. Classification metadata can be used by data loss prevention (DLP), encryption, and other security solutions to determine what information is sensitive and how it should be protected.
- Monitor and maintain
- Be prepared to monitor and maintain the organization’s data classification system and make any necessary updates. Classification policies should be dynamic. You should establish a review and update process that includes encouraging user adoption and ensuring that your approach continues to meet the changing needs of the business.
Be selective
- Classifying all data is an expensive and cumbersome activity that few firms can handle. A good retention policy can help reduce datasets and streamline your efforts. Start by selecting specific types of data to categorize according to your privacy needs and add more security for increasingly confidential data.
All Data Should Be Equal
- Data classification in the process up to the destruction of information; It helps your organization ensure that its data is effectively protected, stored and managed. Putting data classification at the center of your data protection strategy allows you to reduce risks for sensitive data, improve decision making, and increase the effectiveness of DLP, encryption and other security controls. By creating a simple classification scheme, comprehensively evaluating and locating data, and implementing the right solutions, your organization will; It provides a simplified, streamlined system for ensuring the appropriate use of sensitive data and mitigating threats to your business processes.